'분류 전체보기'에 해당되는 글 180건
- 2018.05.07 KL divergence (두 확률분포를 비교하자) 1
- 2017.10.29 selenium in ubuntu
- 2017.03.22 oozie command 정리
- 2016.09.08 DB table 크기 확인
- 2016.08.30 [Elasticsearch] Decay function 에 대해서 (수정중)
- 2016.07.22 Binary Search (이진검색)
- 2016.07.21 maven yum install
- 2016.07.15 zeppelin 에러
- 2016.07.07 pip install mysql-python 실패시에
- 2016.07.05 통계학 시작 1



1) Submit job:$ oozie job -oozie htp://localhost:11000/oozie -config oozieProject/workflowHdfsAndEmailActions/job.properties -submit job: 0000001-130712212133144-oozie-oozi-W
2) Run job:$ oozie job -oozie htp://localhost:11000/oozie -start 0000001-130712212133144-oozie-oozi-W
3) Check the status:$ oozie job -oozie htp://localhost:11000/oozie -info 0000001-130712212133144-oozie-oozi-W
4) Suspend workflow:$ oozie job -oozie htp://localhost:11000/oozie -suspend 0000001-130712212133144-oozie-oozi-W
5) Resume workflow:$ oozie job -oozie htp://localhost:11000/oozie -resume 0000001-130712212133144-oozie-oozi-W
6) Re-run workflow:$ oozie job -oozie htp://localhost:11000/oozie -config oozieProject/workflowHdfsAndEmailActions/job.properties -rerun 0000001-130712212133144-oozie-oozi-W
7) Should you need to kill the job:$ oozie job -oozie htp://localhost:11000/oozie -kill 0000001-130712212133144-oozie-oozi-W
8) View server logs:$ oozie job -oozie htp://localhost:11000/oozie -logs 0000001-130712212133144-oozie-oozi-W
Logs are available at:/var/log/oozie on the Oozie server.
'프로그래밍 > Hadoop ETC' 카테고리의 다른 글
| [Hadoop] 작은 파일들 합치기 (0) | 2016.05.10 |
|---|---|
| [HIVE] patition by 쿼리 (0) | 2015.12.08 |
| [Hadoop] hdfs에 데이터 올라가는 과정 (0) | 2015.08.21 |
| [Hadoop] OOZIE 사용 (with hive, sqoop) (0) | 2015.06.17 |
| [Hadoop] hive 파티션 설정, external table, datatype (0) | 2015.06.13 |
SELECT
table_name,
table_rows,
round(data_length/(1024*1024),2) as 'DATA_SIZE(MB)',
round(index_length/(1024*1024),2) as 'INDEX_SIZE(MB)'
FROM information_schema.TABLES
where table_schema = 'DBNAME'
GROUP BY table_name
ORDER BY data_length DESC
LIMIT 10;
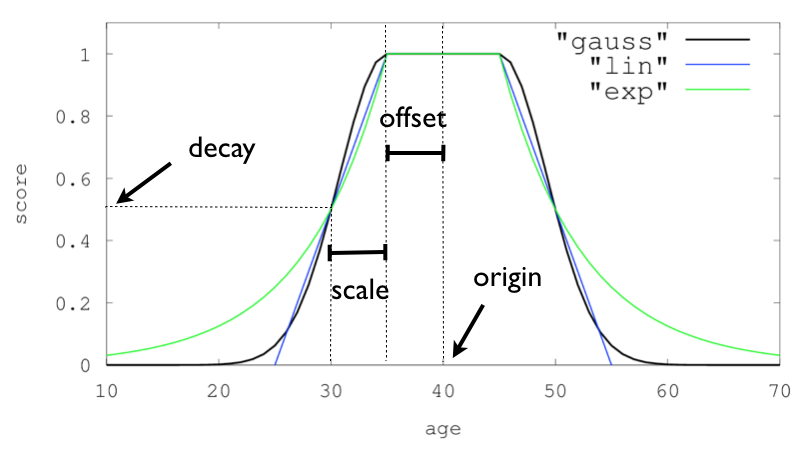
Elasticsearch 의 Decay function 들을 사용해보고 그 과정들을 기록해보고자 한다.
Elasticsearch에서 검색을 하다보면 일반 수치 필드에 대한 scoring 이 필요할 때가 있다. 예를 들면 유투브의 VIEW 수에 따라 높을수록 High score 를 갖게 하는 것이다. 물론 sort 쿼리로 view수를 내림차순으로 하게 할 수도 있지만, 다른 필드와의 복합적인 연산이 어려워진다.
그래서 Elasticsearch 에서 제공하는 decay_function들을 사용할 필요가 생기게 된다. decay_function 을 이용하여 수치적(numerical) 필드에 대한 nomalized scoring을 할 수 있다.
Elastic공식 문서에서 보게 되면 본 목적은 지리적 거리(geographic) 혹은 수치적 데이터에서 검색하려는 수치 인근의 데이터를 높은 순위로 검색하게 하기 위함이다. 또한 0~1 까지로 nomalize score 를 내어주기 때문에 다른 쿼리들과 같이 사용하여 복합 score 를 만들어내기도 좋다. 아래는 그 예시이다.
Elasticsearch에서 검색을 하다보면 일반 수치 필드에 대한 scoring 이 필요할 때가 있다. 예를 들면 유투브의 VIEW 수에 따라 높을수록 High score 를 갖게 하는 것이다. 물론 sort 쿼리로 view수를 내림차순으로 하게 할 수도 있지만, 다른 필드와의 복합적인 연산이 어려워진다.
그래서 Elasticsearch 에서 제공하는 decay_function들을 사용할 필요가 생기게 된다. decay_function 을 이용하여 수치적(numerical) 필드에 대한 nomalized scoring을 할 수 있다.
Elastic공식 문서에서 보게 되면 본 목적은 지리적 거리(geographic) 혹은 수치적 데이터에서 검색하려는 수치 인근의 데이터를 높은 순위로 검색하게 하기 위함이다. 또한 0~1 까지로 nomalize score 를 내어주기 때문에 다른 쿼리들과 같이 사용하여 복합 score 를 만들어내기도 좋다. 아래는 그 예시이다.
function_score": {
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}
'프로그래밍 > ElasticSearch' 카테고리의 다른 글
| [Elasticsearch] 분산환경에서의 인덱스용량과 검색 속도 (0) | 2016.02.21 |
|---|---|
| [Elasticsearch] lucene offsetAttribue (0) | 2015.07.19 |
| [Elasticsearch] Index Mapping with java (0) | 2015.07.15 |
| [Elasticsearch] 플러그인 설치 with jar (0) | 2015.07.09 |
| [Elasticsearch] StringOutofIndex 에러 (0) | 2015.07.09 |
이진 검색 알고리즘(binary search algorithm)은 오름차순으로 정렬된 리스트에서 특정한 값의 위치를 찾는 알고리즘이다. 처음 중간의 값을 임의의 값으로 선택하여, 그 값과 찾고자 하는 값의 크고 작음을 비교하는 방식을 채택하고 있다. 처음 선택한 중앙값이 만약 찾는 값보다 크면 그 값은 새로운 최고값이 되며, 작으면 그 값은 새로운 최하값이 된다. 검색 원리상 정렬된 리스트에만 사용할 수 있다는 단점이 있지만, 검색이 반복될 때마다 목표값을 찾을 확률은 두 배가 되므로 속도가 빠르다는 장점이 있다. 이진 검색은 분할 정복 알고리즘의 한 예이다.
def binarySearch(array, value, low=0, high=0): if low > high: return False mid = (low+high) // 2 if array[mid] > value: return binarySearch(array, value, low, mid-1) elif array[mid] < value: return binarySearch(array, value, mid+1, high) else: return mid
$ sudo wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
$ sudo yum install apache-maven
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
위 에러 사항
이유 jackson lib 여러개 있어서 생김.
zeppelin packaging 후에
zepplein-server/target/lib
zeppelin-zengine/target/lib
jackson-databind-2.5.x.jar 를 삭제한 후 재시작한다.
sudo apt-get install libmysqlclient-dev
'프로그래밍' 카테고리의 다른 글
| git 변경된 파일 무시하기. (0) | 2016.07.04 |
|---|---|
| Java 메모리 관리(스택프레임) (1) | 2016.06.05 |
| 유니코드와 인코딩에 대하여 (0) | 2016.06.04 |
| strategy pattern(전략 패턴) (0) | 2016.05.29 |
| templete method 패턴 (0) | 2016.05.29 |
통계학의 기본을 곱씹고자 선택한 책.
현재 6장. 문제를 풀어봄으로써 좀더 생각을 하게 해줌

02 기술통계
2.1 자료의 종류와 구조 17
2.2 표를 이용한 자료정리 20
2.3 그래프를 이용한 자료정리 26
2.4 수치를 이용한 자료정리
연습문제 66
03 확률
3.1 기본개념 75
3.2 확률의 이해 78
3.3 확률의 기본정리 87
3.4 조건부확률 92
3.5 독립사건 104
연습문제 109
04 확률분포
4.1 확률변수 115
4.2 확률분포 117
4.3 기댓값 124
4.4 결합분포와 주변분포 133
4.5 공분산과 상관계수 138
연습문제
05 이항분포와 관련 분포
5.1 베르누이분포 145
5.2 이항분포 147
5.3 초기하분포 152
5.4 포아송분포 156
5.5 기타 이산분포* 159
연습문제 163
06 정규분포
6.1 정규분포의 성질 167
6.2 표준정규분포 169
6.3 정규분포의 계산 173
연습문제 178
07 표집분포
7.1 확률표본과 통계량 183
7.2 표집분포 185
7.3 표본평균의 분포와 중심극한정리 189
7.4 이항분포의 정규근사 192
연습문제 195
08 통계적 추론 개요
8.1 모수적 추론 199
8.2 점추정과 중심축량 201
8.3 구간추정과 이해 203
8.4 가설검정의 개념과 원리 206
'데이터eng' 카테고리의 다른 글
| softmax, cross_entropy 에 대하여 (0) | 2016.06.05 |
|---|---|
| sigmoid 함수 미분 과정 (1) | 2016.05.29 |
| [라그랑제 승수]조건부 최적화 문제 풀기 (0) | 2016.01.12 |
| MLE(최우도 추정)에 관해 (0) | 2015.12.31 |
| bayes rule (0) | 2015.12.30 |

