Elasticsearch 의 Decay function 들을 사용해보고 그 과정들을 기록해보고자 한다.
Elasticsearch에서 검색을 하다보면 일반 수치 필드에 대한 scoring 이 필요할 때가 있다. 예를 들면 유투브의 VIEW 수에 따라 높을수록 High score 를 갖게 하는 것이다.
물론 sort 쿼리로 view수를 내림차순으로 하게 할 수도 있지만, 다른 필드와의 복합적인 연산이 어려워진다.
그래서 Elasticsearch 에서 제공하는 decay_function들을 사용할 필요가 생기게 된다. decay_function 을 이용하여 수치적(numerical) 필드에 대한 nomalized scoring을 할 수 있다.
Elastic공식 문서에서 보게 되면 본 목적은 지리적 거리(geographic) 혹은 수치적 데이터에서 검색하려는 수치 인근의 데이터를 높은 순위로 검색하게 하기 위함이다. 또한 0~1 까지로 nomalize score 를 내어주기 때문에 다른 쿼리들과 같이 사용하여 복합 score 를 만들어내기도 좋다.
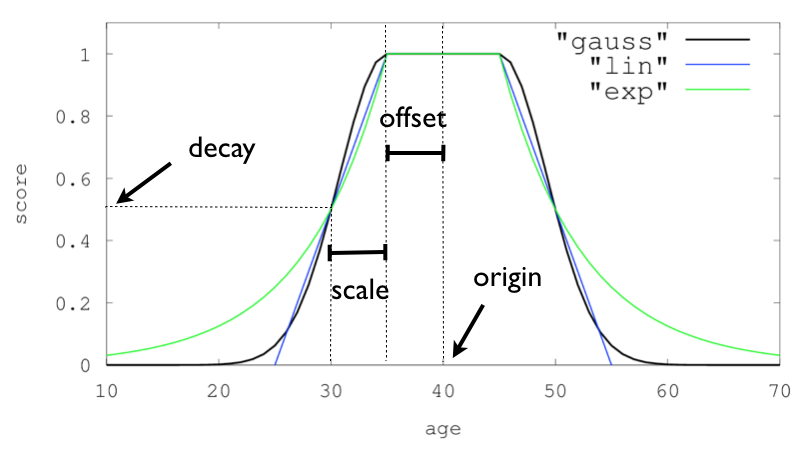
아래는 그 예시이다.
function_score": {
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}