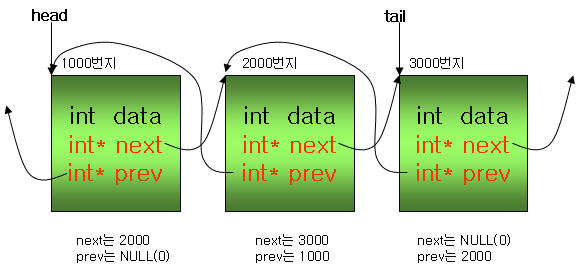
이중 링크드 리스트는 단일 링크드 리스트에 이전 구조체의 번지값을 저장할 수 있는 포인터가 하나 더
추가되는 것이다. 다음 그림을 보며, next외에 prev라는 포인터가 하나 더 존재하며, prev 포인터는 이전
구조체의 메모리 번지를 저장하는 것을 확인할 수 있다.
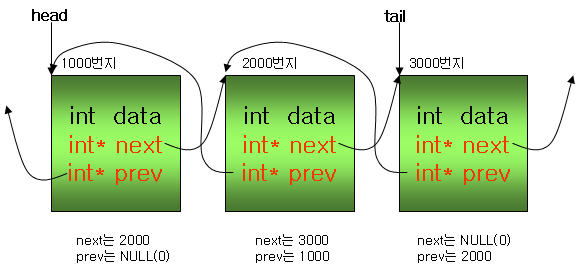
다음은 위 그림에 대한 간단한 예이다.
struct linked_list
{
int data;
int* next;
};
struct linked_list list[3];
struct linked_list* head, *tail;
head = &list[0];
list[0]->next = &list[1]; // 첫 번째 구조체의 next 포인터는 두 번째 구조체(list[1])의 번지값을 갖는다.
list[1]->next = &list[2]; // 두 번째 구조체의 next 포인터는 세 번째 구조체(list[2])의 번지값을 갖는다.
list[2]->next = NULL; // 마지막 리스트는 항상 NULL이 되어야, 링크드 리스트의 끝이 어디인지 판단할 수 있음
list[0]->prev = NULL; // 첫 번째 구조체의 prev는 항상 NULL이 되어야, 링크드 리스트의 처음이 어디인지 알 수 있음
list[1]->prev = &list[0]; // 두 번째 구조체의 prev 포인터는 첫 번째 구조체(list[0])의 번지값을 갖는다.
list[2]->prev = &list[1]; // 세 번째 구조체의 prev 포인터는 두 번째 구조체(list[1])의 번지값을 갖는다.
struct linked_list* p = head; // p는 첫 번째 구조체의 번지
struct linked_list* next = p->next ; // next는 두 번째 구조체의 번지
struct linked_list* next2 = next->next; // next2는 세 번째 구조체의 번지
p->data; // 첫 번째 구조체의 data 값, list[0].data와 동일
next->data; // 두 번째 구조체의 data 값, list[1].data와 동일
next2->data; // 세 번째 구조체의 data 값, list[2].data와 동일
struct linked_list* p = tail; // p는 마지막 구조체의 번지
struct linked_list* prev = p->prev; // prev는 두 번째 구조체의 번지
struct linked_list* prev2 = prev->prev; // prev2는 첫 번째 구조체의 번지
p->data; // 세 번째 구조체의 data 값, list[2].data와 동일
prev->data; // 두 번째 구조체의 data 값, list[1].data와 동일
prev2->data; // 첫 번째 구조체의 data 값, list[0].data와 동일
--------------------------------------------&^.^-----------------------------------------------
#include <stdio.h> // printf, scanf
#include <stdlib.h> // malloc
#include <malloc.h> // malloc
#include <memory.h> // memset
// 구조체 포인터 변수인 next는 다음 구조체의 번지값을 기억하기 위해 사용된다. next가 다음 구조체의
// 번지값을 기억하고 있기 때문에 next를 통해서 구조체를 연결할 수 있다.
struct tag_list
{
int data; // data
struct tag_list* next; // 4바이트 구조체 포인터
struct tag_list* prev; // 4바이트 구조체 포인터
};
// struct tag_list를 좀 더 짧게 재정의한다.
typedef struct tag_list LIST; // struct tag_list 대신에 LIST를 사용할 수 있도록 정의
typedef struct tag_list* PLIST; // struct tag_list* 대신에 PLIST를 사용할 수 있도록 정의
void AddTail( PLIST plist );
void AddHead( PLIST plist );
void PRINT();
void FREE();
// LIST가 순차적으로 여러 개 있을 때, 맨 앞에 있는 LIST의 번지를 head 포인터가 저장하고 있으며,
// 맨 뒤에 있는 구조체의 번지는 tail이 저장한다. head 포인터는 항상 LIST의 선두를 가리키고 있기
// 때문에, head에서부터 구조체를 연속해서 찾아갈 수 있다.
PLIST head = NULL, tail = NULL; // 전역 변수, 맨 앞, 맨 뒤의 구조체 번지를 저장
void main( void )
{
int data = 1;
while( data )
{
PLIST plist;
scanf( "%d", &data );
plist = (PLIST)malloc( sizeof(LIST) ); // 메모리를 12바이트만큼 동적 할당(생성)
memset( plist, 0, sizeof(LIST) ); // 할당 받은 메모리를 0으로 초기화
plist->data = data;
AddTail( plist );
}
PRINT();
}
// 링크드 리스트를 뒤로 추가
void AddTail( PLIST plist )
{
plist->next = NULL; // NULL로 초기화
plist->prev = NULL; // NULL로 초기화
if( !head ) // head 포인터가 아직 아무 것도 가리키지 않으면, if( head == NULL )과 동일
{
head = tail = plist;
return;
}
tail->next = plist; // 다음(next) 포인터 설정
plist->prev = tail; // 이전(prev) 포인터 설정
tail = plist;
}
// 링크드 리스트를 앞으로 추가
void AddHead( PLIST plist )
{
plist->next = NULL;
plist->prev = NULL;
if( !head )
{
head = tail = plist;
return;
}
head->prev = plist; // 이전(prev) 포인터 설정
plist->next = head; // 다음(next) 포인터 설정
head = plist;
}
void PRINT()
{
// 맨 앞의 구조체부터 맨 뒤의 구조체로 순회
PLIST plist = head; // 맨 앞의 링크드 리스트 위치로 설정
while( plist ) // while( plist != NULL )
{
printf( "%d \n", plist->data );
plist = plist->next; // 다음 리스트의 번지값으로 plist의 값을 변경
}
// 맨 뒤의 구조체부터 맨 앞의 구조체로 순회
PLIST plist = tail; // 맨 뒤의 링크드 리스트 위치로 설정
while( plist ) // while( plist != NULL )
{
printf( "%d \n", plist->data );
plist = plist->prev; // 이전 리스트의 번지값으로 plist의 값을 변경
}
}
void FREE()
{
PLIST plist = head;
while( plist )
{
head = plist->next;
free( plist ); // 할당한 메모리 해제
plist = head;
}
head = tail = NULL; // 포인터 초기화, 재 사용 시 필요
}
--------------------------------------------&^.^-----------------------------------------------
아래의 내용은 단일 링크드 리스트와 유사합니다.
malloc() 함수
메모리를 할당하는 malloc 함수는 다음과 같이 사용할 수 있다. malloc() 함수는 void*형을 반환하기 때문에
데이터형을 일치시켜야 한다. 왜 void*형을 반환하는가? 만약 int*형을 반환한다면 int*형만 사용하는 것이고
char*형을 반환한다면, char*형만 사용하는 것이 될 것이다. 그래서 모든 포인터에서 다 사용할 수 있도록
malloc() 함수는 void*형을 리턴한다.
int* pi = (int*)malloc( 4 ); // 4바이트 할당
...
free( pi ); // 할당된 메모리 해제
char* p = malloc( 100 ); // 100 바이트 할당
...
free( p );
이런 원리를 이용해서 다음과 같이 LIST 구조체의 메모리를 할당한다.
plist = (PLIST)malloc( sizeof(LIST) ); // 메모리를 12바이트만큼 동적 할당(생성)
memset( plist, 0, sizeof(LIST) ); // 할당 받은 메모리를 0으로 초기화
malloc() 함수는 메모리 할당 후 그 영역을 초기화하지 않고 돌려 준다. 그러므로 항상 memset() 함수를
사용해서 초기화 해 주는 습관을 갖는 것이 좋다. 위 예제에서는 반드시 초기화할 필요는 없다. 초기화하지
않아도 다른 값으로 초기화되기 때문이다.
링크드 리스트 생성 및 연결
// 링크드 리스트 생성
void AddTail( PLIST plist )
{
plist->next = NULL; // NULL로 초기화
plist->prev = NULL; // NULL로 초기화
if( !head ) // head 포인터가 아직 아무 것도 가리키지 않으면, if( head == NULL )과 동일
{
head = tail = plist;
return;
}
tail->next = plist; // 다음(next) 포인터 설정
plist->prev = tail; // 이전(prev) 포인터 설정
tail = plist;
}
위 코드는 단일 링크드 리스트와 거의 유사하며, 보라색 문장이 새로 추가되었다.
plist->prev = tail; // 이전(prev) 포인터 설정
이 코드는 두 번째 구조체부터 적용된다. 첫 번째 구조체는 위의 코드에서 if( !head )에 의해 head와
tail을 초기화한 후 리턴한다. tail은 첫 번째 구조체의 번지를 갖고 있기 때문에 첫 번째 구조체의 next
에 지금 추가할 구조체의 번지값을 대입한다. 그리고 나서 다음과 같이 tail을 추가할 구조체의 번지로
재 설정한다. 그러면 head와 tail의 값은 서로 틀려지고, tail은 두 번째(또는 마지막) 구조체의 번지를
갖게 된다. 여기서 tail에 추가되는 구조체는 이전 구조체의 번지를 알아야 하기 때문에 현재 생성된
구조체의 prev에 tail 포인터의 값을 먼저 대입한다. 그리고 나서 tail 포인터의 값을 다음과 같이 변경
해 준다.
tail = plist;
링크드 리스트로 연결된 구조체를 맨 앞부터 맨 뒤까지 접근
void PRINT()
{
// 맨 앞의 구조체부터 맨 뒤의 구조체로 순회
PLIST plist = head; // 맨 앞의 링크드 리스트 위치로 설정
while( plist ) // while( plist != NULL )
{
printf( "%d \n", plist->data );
plist = plist->next; // 다음 리스트의 번지값으로 plist의 값을 변경
}
// 맨 뒤의 구조체부터 맨 앞의 구조체로 순회
PLIST plist = tail; // 맨 뒤의 링크드 리스트 위치로 설정
while( plist ) // while( plist != NULL )
{
printf( "%d \n", plist->data );
plist = plist->prev; // 이전 리스트의 번지값으로 plist의 값을 변경
}
}
단일 링크드 리스트가 항상 맨 앞에서 접근하는 것이 비해, 이중 링크드 리스트는 맨 앞 또는
맨 뒤에서 접근이 가능하다. 맨 앞부터 접근하려면 head 포인터를 사용하고, 맨 뒤부터 접근하려면
tail 포인터를 사용한다. 여기서 주의해야 할 것은 맨 앞부터 순회할 때는
plist = plist->next;
를 사용하고, 맨 뒤부터 순회할 때는
plist = plist->prev;
를 사용한다는 것이다. 이 것은 실수하기 쉬우므로 주의하도록 하자.
링크드 리스트의 메모리 해제
void FREE()
{
PLIST plist = head;
while( plist )
{
head = plist->next;
free( plist ); // 할당한 메모리 해제
plist = head;
}
head = tail = NULL; // 포인터 초기화, 재 사용 시 필요
}
malloc() 함수에 의해 할당된 메모리는 반드시 free() 함수에 의해 해제 되어야 한다. 만약 메모리를
할당한 후 해제하지 않는다면, 언젠가는 메모리가 부족해질 것이다. 그러므로 malloc()에 의해 할당된
메모리는 free() 함수로 해제하도록 하자.
PLIST plist = head;
우선 맨 처음의 구조체 번지를 갖고 있는 head 포인터로 초기화한다.
while( plist )
{
...
}
plist가 NULL이 아닌 동안 메모리를 루프를 순환한다.
head = plist->next;
head 구조체 포인터는 더 이상 필요하지 않기 때문에 다음 구조체의 번지를 임시 저장한다.
free( plist ); // 할당한 메모리 해제
plist가 가리키는 번지부터 메모리 할당을 해제한다.
plist = head;
plist에 다음 구조체 번지를 대입한다. head에는 조금 전에 다음 구조체의 번지를 임시로
저장해 두었다. 이렇게 끝까지( plist->next가 NULL일 때까지) 링크드 리스트를 순회화면서
malloc() 함수에 의해 할당 받은 메모리를 모두 해제한다.
head = tail = NULL; // 포인터 초기화, 재 사용 시 필요
모든 링크드 리스트가 해제 되었기 때문에 head와 tail은 NULL로 초기화한다.
--------------------------------------------&^.^-----------------------------------------------
다음은 그림으로 알아보는 이중 링크드 리스트의 모습이다.
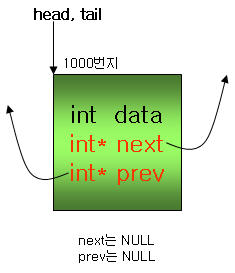
head와 tail 구조체 포인터는 처음에 NULL로 초기화되어 있다.
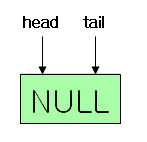
여기에 구조체 하나를 추가하면, head와 tail은 첫 번째 구조체의 번지값을 갖게 되며,
구조체 안의 next와 prev는 각각 NULL로 초기화 된다.
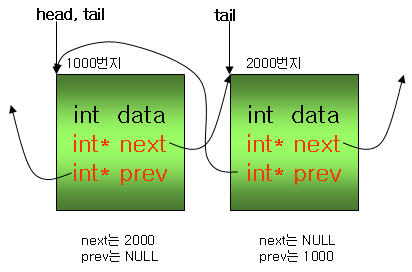
위 구조체에 다른 구조체를 하나 추가하면, head는 그대로 있고, tail은 다음 구조체의 번지값으로 변경된다.
또한 위 구조체의 next는 다음 구조체의 번지값인 2000으로 변경된다. 새로 추가된 구조체의 next와 prev도
적절하게 변경되어야 하는데, next는 다음 구조체가 없으므로 NULL로, prev는 이전 구조체의 번지값인 1000을
갖게 된다. tail이 가리키는 구조체의 prev는 어느 구조체를 가리키고 있는가? 바로 이전 구조체를 가리키고
있다. 그러므로 두 개의 구조체가 이중으로 연결된 모습을 확인할 수 있다.
여기에 구조체를 하나 더 추가하면 다음과 같이 된다. tail 포인터는 마지막 구조체로 이동하고
2000번지에 있는 두 번째 구조체의 next는 3000번지로 변경된다. 그리고 새로 추가되는 3000번지의
구조체에 next는 다음 구조체가 없기 때문에 NULL로 설정된다. 또한 3000번지의 prev는 이전 구조체의
번지인 2000을 갖게 된다.
우리는 head나 tail을 통해서 모든 구조체를 차례대로 옮겨 가면서 그 값을 참조할 수 있는데, head를 통해서
첫 번째 구조체를 찾을 수 있고, 첫 번째 구조체의 next를 통해서 그 다음 구조체(두 번째 구조체)를 찾을 수
있다. 그리고 두 번째 구조체에 있는 next 포인터를 통해서 그 다음 구조체를 찾을 수 있다. 이렇게 구조체가
연속적으로 연결되어 있는 것을 링크드 리스트라 한다.
--------------------------------------------&^.^-----------------------------------------------
링크드 리스트에서 구조체 제거
링크드 리스트에서 특정한 구조체를 제거하는 그리 어렵지 않다. 구조체의 제거는 3가지로 구분할 수 있다.
▷ 맨 앞의 구조체를 제거하는 경우
▷ 맨 뒤의 구조체를 제거하는 경우
▷ 중간의 구조체를 제거하는 경우
다음과 같이 링크드 리스트가 있다고 가정하자.
⊙ 맨 앞의 구조체를 제거하는 경우
void Remove( PLIST plist )
{
if( !plist ) return; // NULL 포인터이면 리턴
if( plist == head ) // 맨 앞의 구조체
{
PLIST pRemove;
pRemove = head; // head를 임시 저장, pRemove = plist; 도 가능
head = plist->next; // head를 다음 구조체를 가리키도록 설정
head->prev = NULL; // 이전 구조체 번지를 NULL로 설정
free( pRemove ); // 메모리 해제
if( head == NULL ) tail = NULL; // 더 이상 구조체가 없으면 tail을 NULL로 초기화
}
}
맨 앞의 구조체가 제거되면 1000번지는 메모리가 해제(free)되고, head는 2000번지를 가리키도록 설정된다.
또한 2000번지에 있는 prev는 더 이상 1000번지를 가리키면 안되므로 NULL로 설정한다.
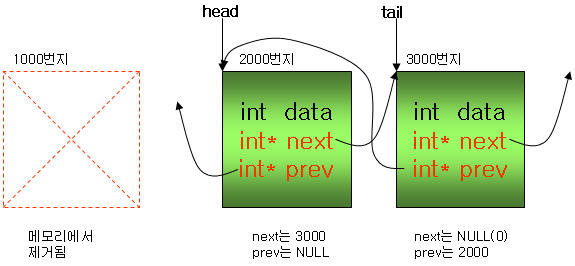
⊙ 맨 뒤의 구조체를 제거하는 경우
void Remove( PLIST plist )
{
if( !plist ) return; // NULL 포인터이면 리턴
if( plist == tail ) // 맨 뒤의 구조체
{
PLIST pRemove;
pRemove = tail; // tail을 임시 저장, pRemove = plist; 도 가능
tail = plist->prev; // tail을 이전 구조체를 가리키도록 설정
tail->next = NULL; // 다음 구조체 번지를 NULL로 설정
free( pRemove ); // 메모리 해제
if( tail == NULL ) head = NULL; // 더 이상 구조체가 없으면 head를 NULL로 초기화
}
}
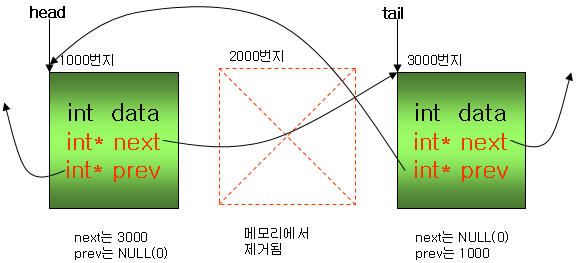
맨 뒤의 구조체가 제거되면 3000번지는 메모리가 해제(free)되고, tail은 2000번지를 가리키도록 설정된다.
또한 2000번지에 있는 next는 더 이상 3000번지를 가리키면 안되므로 NULL로 설정한다.
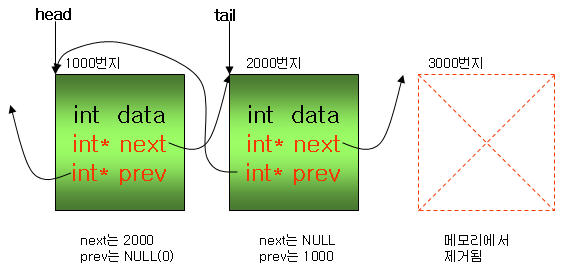
⊙ 중간의 구조체를 제거하는 경우
void Remove( PLIST plist )
{
if( !plist ) return; // NULL 포인터이면 리턴
if( plist != head && plist != tail ) // 중간의 구조체
{
PLIST pRemove;
pRemove = plist; // plist를 임시 저장
if( plist->prev )
plist->prev->next = plist->next; // 이전 구조체(1000번지)의 next와 다음 구조체(3000번지)를 연결
if( plist->next )
plist->next->prev = plist->prev; // 다음 구조체(3000번지)의 prev와 이전 구조체(1000번지)를 연결
free( pRemove ); // 메모리 해제
if( tail == NULL ) head = NULL; // 더 이상 구조체가 없으면 head를 NULL로 초기화
}
}
중간의 구조체가 제거되면 2000번지는 메모리가 해제(free)된다. 이 때 중요한 것은 링크드 리스트의 연결이 중간에
끊기지 않도록 이전 구조체와 다음 구조체간에 연결을 설정하는 것이다. 위의 코드에서 다음은
if( plist->prev ) // 이전 구조체가 있는지 검사
plist->prev->next = plist->next; // 이전 구조체(1000번지)의 next와 다음 구조체(3000번지)를 연결
이전 구조체가 있을 경우, 이전 구조체의 next 포인터를 3000번지로 설정하는 것이다. 이 것을 풀어서 써 보면
다음과 같다.
if( plist->prev )
{
PLIST pTemp;
pTemp = plist->prev;
pTemp->next = plist->next;
}
또한 다음과 같이 제거되는 구조체 다음의 구조체에 대하여 prev를 설정해야 한다.
if( plist->next )
plist->next->prev = plist->prev; // 다음 구조체(3000번지)의 prev와 이전 구조체(1000번지)를 연결
이 코드를 풀어서 써 보면 다음과 같다.
if( plist->next )
{
PLIST pTemp;
pTemp = plist->next;
pTemp->prev = plist->prev;
}
다음은 전체 소스 코드이다.
void Remove( PLIST plist )
{
if( !plist ) return; // NULL 포인터이면 리턴
if( plist == head ) // 맨 앞의 구조체
{
PLIST pRemove;
pRemove = head; // head를 임시 저장, pRemove = plist; 도 가능
head = plist->next; // head를 다음 구조체를 가리키도록 설정
head->prev = NULL; // 이전 구조체 번지를 NULL로 설정
free( pRemove ); // 메모리 해제
if( head == NULL ) tail = NULL; // 더 이상 구조체가 없으면 tail을 NULL로 초기화
return;
}
if( plist == tail ) // 맨 뒤의 구조체
{
PLIST pRemove;
pRemove = tail; // tail을 임시 저장, pRemove = plist; 도 가능
tail = plist->prev; // tail을 이전 구조체를 가리키도록 설정
tail->next = NULL; // 다음 구조체 번지를 NULL로 설정
free( pRemove ); // 메모리 해제
if( tail == NULL ) head = NULL; // 더 이상 구조체가 없으면 head를 NULL로 초기화
return;
}
if( plist != head && plist != tail ) // 중간의 구조체 if() {}은 생략 가능
{
PLIST pRemove;
pRemove = plist; // plist를 임시 저장
if( plist->prev )
plist->prev->next = plist->next; // 이전 구조체(1000번지)의 next와 다음 구조체(3000번지)를 연결
if( plist->next )
plist->next->prev = plist->prev; // 다음 구조체(3000번지)의 prev와 이전 구조체(1000번지)를 연결
free( pRemove ); // 메모리 해제
if( tail == NULL ) head = NULL; // 더 이상 구조체가 없으면 head를 NULL로 초기화
}
}
--------------------------------------------&^.^-----------------------------------------------
링크드 리스트의 중간에 구조체 추가
링크드 리스트의 끝( AddTail()함수 )과 맨 앞( AddHead() 함수 )에 구조체를 추가하는 것은 위의 예제에서
이미 알아 보았다. 링크드 리스트의 중간에 구조체를 추가하는 것은 그리 어려운 작업이 아니며, next와 prev를
잘 설정하면 된다.
다음과 같이 링크드 리스트가 있다고 가정하자.
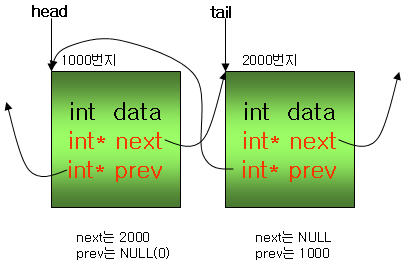
위 그림의 head와 tail 사이에 새로운 구조체를 추가하려면, 1000번지의 next와 2000번지의 prev가 새로 생성
되는 구조체를 가리키도록 수정되어야 한다. head의 next는 새로 생성되는 3000번지의 값으로 변경이 되어야
하고, tail의 prev 또한 새로 생성되는 3000번지의 값으로 변경이 되어야 한다.
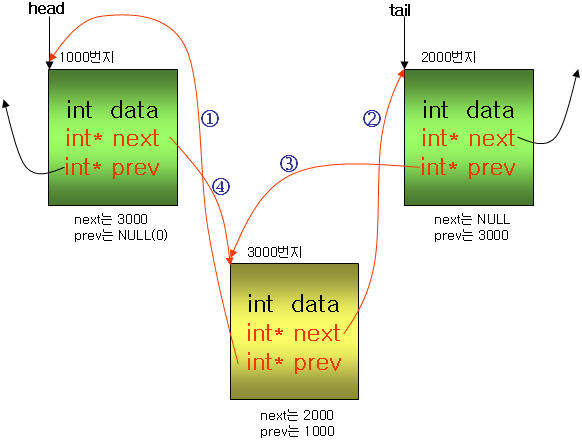
다음은 소스 코드이다.
void AddMiddle( PLIST plist, PLIST node )
{
if( !plist ) return; // NULL 포인터이면 리턴
if( !node ) return; // node가 존재하지 않으면 리턴
plist->prev = node; // 위 그림의 j
plist->next = node->next; // 위 그림의 k
if( node->next )
node->next->prev = plist; // 위 그림의 l
node->next = plist; // 위 그림의 m
}