


'프로그래밍 > 임베디드' 카테고리의 다른 글
| 7segment (0) | 2013.05.23 |
|---|---|
| Led (0) | 2013.05.23 |
| linux kernel build (0) | 2013.05.23 |
| 임베디드 시스템 구성 리눅스 소프트웨어 (0) | 2013.05.23 |
| HBE-SM5-S4210 M3(FPGA) Module (0) | 2013.05.23 |
| 7segment (0) | 2013.05.23 |
|---|---|
| Led (0) | 2013.05.23 |
| linux kernel build (0) | 2013.05.23 |
| 임베디드 시스템 구성 리눅스 소프트웨어 (0) | 2013.05.23 |
| HBE-SM5-S4210 M3(FPGA) Module (0) | 2013.05.23 |
리눅스 시스템 소프트웨어
•부트로더 : uboot-s4210
•리눅스 커널 : linux-2.6.35-s4210
•루트파일 시스템 : glibc-2.10.1, BusyBox v1.9.1 등
•크로스 컴파일러 : gcc 4.4.1
•Application module의 peripheral device 드라이버 모듈
-LED Device Driver Module
-7-Segment Device Driver Module
-TextLCD Device Driver Module
-DotLED Device Driver Module
-Keypad Device Driver Module
-Dip Switch Device Driver Module
-Base LED Device Driver Module
-Piezo Device Driver Module
-Base 7-Segment Device Driver Module
-OLED Device Driver Module
| 7segment (0) | 2013.05.23 |
|---|---|
| Led (0) | 2013.05.23 |
| linux kernel build (0) | 2013.05.23 |
| bootloader (0) | 2013.05.23 |
| HBE-SM5-S4210 M3(FPGA) Module (0) | 2013.05.23 |
HBE-SM5-S4210 M3(FPGA) Module
•Character LCD(16 * 2)
•OLED
•6Digit 7-Segment
•18,752 Logic Elements FPGA EP2C20
•7 * 5 Dot Matrix 2ea
•4 * 4 Keypad
•8point DIP Switch 2ea
•LED 8ea
•Piezo
•Tact Switch 4ea
•Full Color LED
•Motor driver
| 7segment (0) | 2013.05.23 |
|---|---|
| Led (0) | 2013.05.23 |
| linux kernel build (0) | 2013.05.23 |
| bootloader (0) | 2013.05.23 |
| 임베디드 시스템 구성 리눅스 소프트웨어 (0) | 2013.05.23 |
TCP/IP 통신 함수 사용 순서
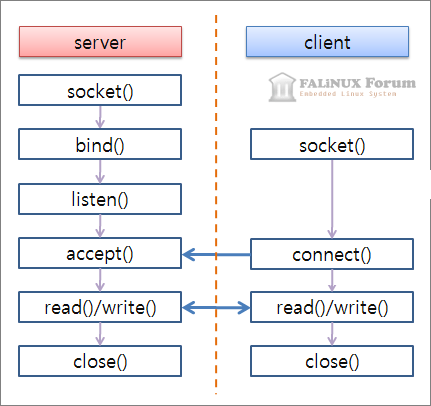
TCP/IP 예제 소개
TCP/IP 예제를 서버와 클라이언트로 나누어서 설명을 드리도록 하겠습니다.
서버 프로그램
서버 프로그램에서 사용해야할 함수와 순서는 아래와 같습니다.
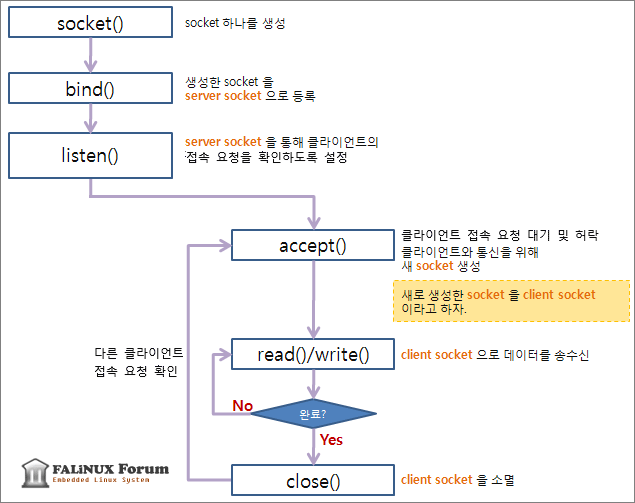
bind() 함수를 이용하여 socket에 server socket 에 필요한 정보를 할당하고 커널에 등록int server_socket;
server_socket = socket( PF_INET, SOCK_STREAM, 0);
if (-1 == server_socket)
{
printf( "server socket 생성 실패");
exit( 1) ;
}
struct sockaddr_in server_addr;
memset( &server_addr, 0, sizeof( server_addr);
server_addr.sin_family = PF_INET; // IPv4 인터넷 프로토롤
server_addr.sin_port = htons( 4000); // 사용할 port 번호는 4000
server_addr.sin_addr.s_addr = htonl( INADDR_ANY); // 32bit IPV4 주소
if( -1 == bind( server_socket, (struct sockaddr*)&server_addr, sizeof( server_addr) ) )
{
printf( "bind() 실행 에러n");
exit( 1);
}
if( -1 == listen( server_socket, 5))
{
printf( "대기상태 모드 설정 실패n");
exit( 1);
}
int client_addr_size;
client_addr_size = sizeof( client_addr);
client_socket = accept( server_socket, (struct sockaddr*)&client_addr,
&client_addr_size);if ( -1 == client_socket)
{
printf( "클라이언트 연결 수락 실패n");
exit( 1);
}
read ( client_socket, buff_rcv, BUFF_SIZE);
sprintf( buff_snd, "%d : %s", strlen( buff_rcv), buff_rcv);
write( client_socket, buff_snd, strlen( buff_snd)+1); // +1: NULL까지 포함해서 전송
close( client_socket);
클라이언트 프로그램
클라이언트 프로그램은 서버에 비해 간단합니다. 바로 설명 들어갑니다.
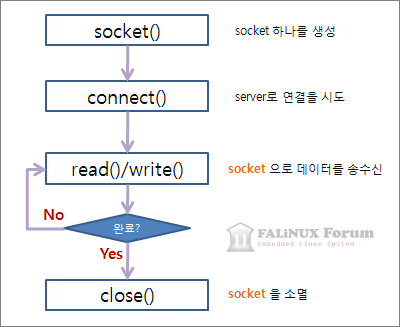
connect()를 이용하여 서버로 접속을 시도합니다.int client_socket;
client_socket = socket( PF_INET, SOCK_STREAM, 0);
if( -1 == client_socket)
{
printf( "socket 생성 실패n");
exit( 1);
}
struct sockaddr_in server_addr;
memset( &server_addr, 0, sizeof( server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons( 4000);
server_addr.sin_addr.s_addr= inet_addr( "127.0.0.1"); // 서버의 주소if( -1 == connect( client_socket, (struct sockaddr*)&server_addr, sizeof( server_addr) ) )
{
printf( "접속 실패n");
exit( 1);
}
write( client_socket, argv[1], strlen( argv[1])+1); // +1: NULL까지 포함해서 전송
read ( client_socket, buff, BUFF_SIZE);
printf( "%sn", buff);
close( client_socket);
서버 프로그램 소스
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
#define BUFF_SIZE 1024
int main( void)
{
int server_socket;
int client_socket;
int client_addr_size;
struct sockaddr_in server_addr;
struct sockaddr_in client_addr;
char buff_rcv[BUFF_SIZE+5];
char buff_snd[BUFF_SIZE+5];
server_socket = socket( PF_INET, SOCK_STREAM, 0);
if( -1 == server_socket)
{
printf( "server socket 생성 실패n");
exit( 1);
}
memset( &server_addr, 0, sizeof( server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons( 4000);
server_addr.sin_addr.s_addr= htonl( INADDR_ANY);
if( -1 == bind( server_socket, (struct sockaddr*)&server_addr, sizeof( server_addr) ) )
{
printf( "bind() 실행 에러n");
exit( 1);
}
while( 1)
{
if( -1 == listen(server_socket, 5))
{
printf( "대기상태 모드 설정 실패n");
exit( 1);
}
client_addr_size = sizeof( client_addr);
client_socket = accept( server_socket, (struct sockaddr*)&client_addr, &client_addr_size);
if ( -1 == client_socket)
{
printf( "클라이언트 연결 수락 실패n");
exit( 1);
}
read ( client_socket, buff_rcv, BUFF_SIZE);
printf( "receive: %sn", buff_rcv);
sprintf( buff_snd, "%d : %s", strlen( buff_rcv), buff_rcv);
write( client_socket, buff_snd, strlen( buff_snd)+1); // +1: NULL까지 포함해서 전송
close( client_socket);
}
}
클라이언트 프로그램 소스
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/socket.h>
#include "sample.h"
#define BUFF_SIZE 1024
int main( int argc, char **argv)
{
int client_socket;
struct sockaddr_in server_addr;
char buff[BUFF_SIZE+5];
client_socket = socket( PF_INET, SOCK_STREAM, 0);
if( -1 == client_socket)
{
printf( "socket 생성 실패n");
exit( 1);
}
memset( &server_addr, 0, sizeof( server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons( 4000);
server_addr.sin_addr.s_addr= inet_addr( "127.0.0.1");
if( -1 == connect( client_socket, (struct sockaddr*)&server_addr, sizeof( server_addr) ) )
{
printf( "접속 실패n");
exit( 1);
}
write( client_socket, argv[1], strlen( argv[1])+1); // +1: NULL까지 포함해서 전송
read ( client_socket, buff, BUFF_SIZE);
printf( "%sn", buff);
close( client_socket);
return 0;
}| Makefile 만들기 (0) | 2013.06.04 |
|---|---|
| scanf 의 입력개념 (0) | 2013.04.20 |
| Stack 과 heap (메모리구조) (0) | 2013.04.19 |
| kernel 에서 쓰이는 자료구조 red black tree (3) | 2013.04.19 |
| Visual studio가 잊어버리게 하는 개념(compile with gcc) (0) | 2013.04.19 |
1. 동기화 개체에 대한 잘못된 생각들
스레드를 동기화한다 함은 스레드 간의 실행순서를 정하거나, 스레드 간 특정작업이 동시에 일어나지 않도록 구현하는 것을 말합니다.
1) Manager Thread가 Worker Thread를 생성한 후, Worker Thread의 초기화가 끝날 때까지 기다려야 하는 경우. 이런 경우에는 보통 Event 개체나 메시지를 사용합니다.
2) 전역 데이터에 접근할 때에 한번에 스레드 한개씩만 해당 데이터를 사용하도록 구현하는 경우 : 이 경우에는 보통 CriticalSection 을 사용합니다. 일반적으로 스레드 동기화라 함은 이러한 경우를 말합니다.
3) 일정 숫자 이상의 스레드(혹은 프로세스)가 동시에 특정 자원을 사용하거나 동작하지 못하도록 하는 경우 : 이 경우에는 보통 Semaphore를 사용합니다.
CriticalSection을 사용하는 데에 있어서 초보자분들은 다음과 같은 착각을 하기 쉽습니다.
착각1) EnterCriticalSection()을 호출하면 Data에 Lock이 걸리고 다른 Thread가 접근하지 못하게 된다. (X)
==> CriticalSection 등의 동기화 개체에 Lock을 건다 함은 화장실이라는 Resource에 문을 걸어 잠그는 개념이 아니라, 화장실의 문에 "사용중"이라고 써붙이는 개념입니다. 이게 무슨 얘기냐 하면, "g_szData 라는 Data에 접근할 때는 crit_szData에 Lock을 걸어야 한다"라고 개발자가 스스로 규칙을 세우고, 코드의 모든 부분에서 g_szData를 사용할 때 CriticalSection에 Lock을 걸도록 구현해야 한다는 뜻입니다. 화장실의 문에 "사용중"이라고 써붙이고 들어갔는데, 어떤 사람이 문에 붙어있는 표시를 확인하지 않고 문을 열고 들어간다면? 운이 좋으면 문제가 안생기겠지만 재수가 없으면 민망한 상황이 벌어질 것입니다.
엄밀히 말하면 데이터에 동기화개체는 스레드 들이 특정 데이터에 동시 Read/Write하지 못하도록 하는 기능을 제공하지 않습니다. 단지 동기화개체에 동시에 Lock을 걸지 못하는 기능을 제공할 뿐이죠. :)
착각2) 데이터에 Read할 때는 동기화가 필요 없다. 따라서 EnterCriticalSection은 Data에 Write를 수행할 때만 수행하면 된다. (X)
==> Data를 Read하는 스레드에서는 그냥 Read를 하면서 Data에 Write를 하는 스레드에서만 Lock을 건다고 해서 다른 스레드가 그 Data에 접근을 못하게 되는 것이 아닙니다. 어떤 CriticalSection에 Lock을 건다고 해서 스레드간 ContextSwitching이 중지되는 건 더더욱 아닙니다. 보호하고자 하는 데이터를 참조하는 모든 부분에 동기화 처리를 해주지 않으면 동기화 개체를 사용하는 것은 아무런 의미도 없습니다.
간단하게 생각하면 CriticalSection이란 보호할 데이터를 사용하는 중에 BOOL형 변수에 "사용중"이라는 의미로 "TRUE" 값을 Setting하는 이상의 의미는 없습니다. 단지 두 Thread에서 동시에 TRUE를 설정하지 못하도록 OS에서 보장해준다는 점과 TRUE를 Setting하려고 할 때 이미 TRUE라는 값이 Setting되어 있다면 이 변수가 FALSE로 바뀔 때까지 스레드가 BLOCK되는 등의 처리가 자동으로 구현되어 있다는 정도가 차이가 있을 뿐입니다.
단지 프로그램 전체에 걸쳐서 어떠한 "Write"도 수행되지 않고 "Read"만 수행되는 데이터라면 동기화가 필요 없습니다.
대부분의 개발자 분들은 이런 얘길 보면서 "이렇게 당연한 얘기를 왜 하나?"라고 생각하시겠지만... 바로 얼마 전에 십 수년간 개발을 하신 서버 개발자께서 "CriticalSection에 Lock을 걸면 말이쥐... 다른 스레드들은 이 데이터에 접근을 못하게 되는 거란다"라고 친절하게 설명해주시는 걸 듣고... 까무라치는 줄 알았습니다. ㅡ.ㅡ
※ 선언 함수나 초기화 함수를 보면 알수 있듯이, CriticalSection은 그 자체로서 어떠한 데이터와도 연관되지 않습니다. 어떠한 데이터를 보호하는데 어떤 CriticalSection 개체를 사용하겠다 하는 것은 순전히 개발자의 로직상으로 구현되는 부분입니다. 위에서 얘기했듯이 OS에서는 동시에 한개의 스레드만 EnterCriticalSection에 성공할 수 있다는 것 외에는 아무것도 보장하지 않습니다. 나머지는 개발자의 몫인 거죠.
2. Case I : Multiple-Reader + Multiple-Writer 환경 (CriticalSection Per Data Model)
멀티스레드 환경에서 발생할 수 있는 가장 일반적인 경우는 다수의 스레드가 동시에 데이터를 읽고 쓰는 경우입니다. 이 경우에는 어떠한 "읽기"와 "읽기", "읽기"와 "쓰기" 혹은 "쓰기"와 "쓰기" 도 동시에 발생해서는 안되며, 완전하게 동시접속이 차단되어야 합니다. 이렇게 처리하는 것을 직렬화(Serialize)한다고 합니다.
이런 환경을 구현하기 위해서는 CriticalSection을 접속하고자 하는 Data의 수만큼 만들고, (읽기/쓰기에 상관없이) Data에 접근할 때마다 해당 Data에 Matching 되는 CriticalSection에 대해 EnterCriticalSection을 수행해주어야 합니다. 말하자면 "CriticalSection Per Data" 정도 되겠네요.
가장 안전한 환경이 구현되지만, 병렬수행이 불가능해지므로 성능은 최악이 됩니다.
그림으로 표현하면 다음과 같이 되겠네요.

3. Case II : Multiple-Reader + Single-Writer 환경 (CriticalSection Per Thread Model)
모든 스레드가 읽기와 쓰기를 행한다면 Case I 과 같이 직렬화를 시켜야겠지만, 대부분의 Server용 Application에서는 다수의 Worker Thread는 전역 데이터에 대해 Read만을 수행하고 한개의 Manager Thread가 Write를 수행하는 구조인 경우가 많습니다. 대표적인 예가 Manager Thread가 기록한 정책을 참조하여 Worker Thread가 클라이언트의 접속을 처리하는 경우를 예로 들 수 있겠죠. (Thread Pool 이 보통 이런 동작을 합니다.)
이러한 경우는 다음과 같은 특징이 있습니다.
1) Read의 빈도가 매우 높고, Write의 빈도는 낮다.
2) Read와 Read는 동시에 이루어지는 것이 바람직하지만 Write와 Read는 동시에 이루어져선 안된다.
3) WokerThread간의 병렬처리가 이루어져야 하므로 Read의 속도가 매우 중요하며 Write의 성능은 상대로 덜 중요하다.
위의 조건을 만족시키기 위해서는 스레드와 동기화 개체들을 어떤 식으로 구성해야 할까요? 제가 내린 결론은 다음과 같습니다. (더 좋은 방법을 아시는 분은 가르쳐주세요. ^^)
1) WorkerThread 마다 CriticalSection을 하나씩 생성한다. WorkerThread는 각자 자기의 CriticalSection을 가지고 있다. 말하자면 워커스레드가 6개라면 CriticalSection도 6개가 생성되며 이것이 Array처럼 접근되도록 구현된다.
2) WorkerThread 는 작업을 시작할 때마다 자기의 CriticalSection에 대해 EnterCriticalSection()을 호출하고 작업을 끝낸 후에는 LeaveCriticalSection을 호출합니다. 이렇게 되면 각 WorkerThread 간에는 작업이 병렬수행되며, 전역 Data에 대해서도 병렬 Read가 이루어집니다. (이때 ManagerThread 는 쉬고 있겠죠)
3) ManagerThread 가 정책을 업데이트해야 할 때는 For Loop 를 돌면서 모든 CriticalSection에 대해 EnterCriticalSection()을 호출합니다. 일단 ManagerThread가 CriticalSection에 Lock을 걸고 나면 해당 WorkerThread는 새로운 작업을 시작하지 못하기 때문에, For Loop가 끝나게 되면 결과적으로 ManagerThread는 모든 WorkerThread를 정지시키게 됩니다. (이때는 물론 시간이 좀 걸리겠죠? ^^)
4) ManagerThread는 정책을 수정합니다.
5) ManagerThread는 For Loop를 돌면서 모든 CriticalSection에 대해 LeaveCriticalSection()을 호출합니다. 이제 WorkerThread들은 다시 자신의 CriticalSection을 획득하고 밀린 일을 처리할 수 있습니다.
그림으로 표현하면 대략 다음과 같이 되겠네요.
WorkerThread간의 읽기작업을 표현하면 다음과 같습니다.

ManagerThread가 쓰기 작업을 진행할 때는 다음과 같이 됩니다.

말하자면... Write속도를 희생시켜서 Read속도를 증가시킨다고나 할까요? ^^
4. Case III : 동기화를 하지 않는 방법(?)
"멀티스레드 프로그래밍에 관한 고찰 (1)" 에서 논했듯이 멀티스레드가 Data에 동시접근한다고 해도 경우에 따라서는 동기화 하지 않고 사용할 수 있습니다. 만약 이게 가능하다면 멀티스레드 프로그램은 최고의 효율을 얻을 수 있습니다. 이렇게 구성하기에 앞서 해당 Case가 이런 방식으로 구성 가능한지 검토해야 하며, 가능하다면 자료구조가 안전한 동시접근이 가능하도록 설계되어야 합니다.
정수형 Data가 Linked List에 저장되는 경우의 예를 들어 보겠습니다.
1) Data가 변경될 때 Linked List에 Entry가 추가/삭제되는 경우에는 반드시 스레드 동기화가 필요합니다. 반대로 시종일관 LinkedList 자체는 변화가 없이 각 Entry의 정수형 데이터값만 변경시키는 경우에는 동기화 없이도 Concurrent Read/Write가 안전하게 수행될 수 있습니다.
이러한 경우의 예를 들면 오목게임의 바둑판을 들 수 있습니다. 모든 좌표에 대해 게임을 시작하기 전에 19 X 19 개의 좌표 Data를 생성한 후, 게임이 진행되는 동안에는 해당 좌표에 대한 Data(흑/백/無)만 Update될 뿐 새로운 좌표가 추가되지는 않습니다. 이런 경우라면 동기화가 필요하지 않습니다.
2) 만약 Data가 Linked List에 추가/삭제되어야 하는 경우라면, 추가되는 데이터의 "경우의 수"에 대해 생각해보아야 합니다. 경우에 따라서는 Insert될 수 있는 Data의 경우의 수가 한정되어 있어 초기화시에 모든 경우의 수에 대한 메모리를 미리 생성해놓고 시작할 수 있는 경우가 있습니다. 이러한 경우라면 동기화 없이 멀티스레드가 동작할 수 있습니다.
예를 들어, 사내 IP체계를 B Class를 사용하는 회사에서 IP를 사용하는 Mac주소와 사용자 정보를 저장하는 자료구조가 있다고 가정해보겠습니다.
. 새로운 IP가 생성될 때마다 Linked List에 Entry가 생성되는 방식으로 설계한다면 스레드 동기화가 필요하며, 동기화하지 않을 경우 Entry를 LinkedList에 Insert하는 순간 Access Violation이 발생할 수 있습니다.
. 모든 경우의 수 (255 * 255 = 65525개)만큼의 Entry를 처음에 일괄 생성해놓고, 사용하지 않는 IP 에 대해서는 FALSE, 사용하는 IP에 대해선 TRUE를 기록하여 미사용 IP를 관리하고, 사용중인 IP에 대해서는 Mac주소와 사용자정보를 미리 할당된 메모리에 memcpy하는 방식으로 자료구조를 설계할 경우 동기화 처리 없이도 안전하게 Concurrent Read/Write가 가능합니다. 한마디로 "메모리를 희생하여 속도를 향상"시키는 방법이죠 :)
| 멀티스레드에 관한 글 (0) | 2013.04.22 |
|---|---|
| mmap (0) | 2013.04.21 |
예전에는 고사양이라 하면 힘쎈 CPU를 의미했지만 지금 시대의 고사양이란 CPU 여러 개를 의미합니다. 이른바 멀티코어의 시대죠. 예전에 3.4GHz 4CPU가 최고사양 서버였다고 하면 요즘에는 1.6GHz 16Core (4Core * 4ea)가 동급으로 받아들여집니다.

| 멀티스레드에 관하여 2 (0) | 2013.04.22 |
|---|---|
| mmap (0) | 2013.04.21 |
void* mmap(void* start, size_t length, int prot, int flags, int fd, off_t offset);
파일이나 디바이스를 응용 프로그램의 주소 공간 메모리에 대응시킨다.
1인자 => 시작 포인터 주소 (아래의 예제 참조)
2인자 => 파일이나 주소공간의 메모리 크기
3인자 => PROT 설정 (읽기, 쓰기, 접근권한, 실행)
4인자 => flags는 다른 프로세스와 공유할지 안할지를 결정한다.
5인자 => fd는 쓰거나 읽기용으로 열린 fd값을 넣어준다.
6인자 => offset은 0으로 하던지 알아서 조절한다.
int munmap(void* start, size_t length);
할당된 메모리 영역을 해제한다.
1인자 => 위에 mmap으로 지정된 포인터값 넣어주고
2인자 => 위에서 사용했던 length와 동일하게 넣어준다.
(왜냐면.. 할당했던거 동일하게 해제해야 하니깐..)
더 자세한 사항은 man page에 모든게 나와있음.
==============================================================
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | #include <stdio.h>#include <stdlib.h>#include <string.h>#include <fcntl.h>#include "sys/types.h"#include "sys/stat.h"#include "sys/mman.h" /* mmap() is defined in this header */int main (int argc, char *argv[]){ int fdin, fdout; char *src, *dst; struct stat statbuf; if (argc != 3) { printf("usage: a.out <fromfile> <tofile>\n"); return -1; } /* open the input file */ if ((fdin = open (argv[1], O_RDONLY)) < 0) { printf ("can't open %s for reading", argv[1]); return -2; } /* open/create the output file */ if ((fdout = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, S_IRUSR|S_IWUSR)) < 0) { printf ("can't create %s for writing", argv[2]); return -2; } /* find size of input file */ if (fstat (fdin,&statbuf) < 0) { printf ("fstat error"); return -2; } /* go to the location corresponding to the last byte */ if (lseek (fdout, statbuf.st_size - 1, SEEK_SET) == -1) { printf ("lseek error"); return -2; } /* write a dummy byte at the last location */ if (write (fdout, "", 1) != 1) { printf ("write error"); return -2; } /* mmap the input file */ if ((src = mmap(0, statbuf.st_size, PROT_READ, MAP_SHARED, fdin, 0)) == (caddr_t) -1) { printf ("mmap error for input"); return -2; } /* mmap the output file */ if ((dst = mmap(0, statbuf.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, 0)) == (caddr_t) -1) { printf ("mmap error for output"); return -2; } /* this copies the input file to the output file */ memcpy (dst, src, statbuf.st_size); munmap(src, statbuf.st_size); munmap(dst, statbuf.st_size); return 0;} /* main *//* The end of function */</tofile></fromfile></fcntl.h></string.h></stdlib.h></stdio.h> |
1 2 3 4 5 6 7 8 9 | 실행 후 결과 화면 $ ./a.out test test_out$ ls -aldrwxr-xr-x 2 jeon jeon 4096 Jul 17 08:39 .drwx------ 12 jeon jeon 4096 Jul 17 08:39 ..-rwxr-xr-x 1 jeon jeon 6410 Jul 17 08:39 a.out-rw-r--r-- 1 jeon jeon 1844 Jul 17 08:39 mmap.c-rw-r--r-- 1 jeon jeon 469 Jul 17 08:29 test-rw------- 1 jeon jeon 469 Jul 17 08:39 test_out |
| 멀티스레드에 관하여 2 (0) | 2013.04.22 |
|---|---|
| 멀티스레드에 관한 글 (0) | 2013.04.22 |
|
| HttpseverletRequest 정리 (0) | 2014.06.10 |
|---|---|
| Media query에 대한 이해 (0) | 2014.06.06 |
| xml 노드 검색 (0) | 2013.05.30 |
| xml 노드 검색 (0) | 2013.05.30 |
| XML 노드 삽입 (0) | 2013.05.30 |
scanf 함수의 개념은 "입력 버퍼(stdin)에서 format에서 지정한 대로 읽어들
인다" 입니다. 위의 두개의 차이는 다음과 같습니다.
"%d %d" - stdin에서 숫자, 1자 이상의 공백문자(white-space character), 숫
자를 읽어들인다.
"%d %d\n" - stdin에서 숫자, 1자 이상의 공백문자, 숫자, 1자 이상의 공백문
자를 읽어들인다.
C99의 FCD인 N869 문서의 7.19.6.2.5절을 인용하겠습니다.
A directive composed of white-space character(s) is executed by reading
input up to the first non-white-space character (which remains unread),
or until no more characters can be read.
형식(format) 문자열에 있는 공백문자(white-space)는 그 다음에 공백 문자가
아닌 문자(non-white-space)가 올때까지 입력버퍼(stdin)에서 읽어들이라는
뜻입니다. 즉, "%d %d\n"는 숫자 2개, 1자 이상의 공백문자, 공백문자가 아닌
문자를 받아야만 입력이 완전하게 끝나는 것입니다. 참고로 "%d %d\n"과 "%d
%d ", "%d %d\t"는 같은 뜻을 가집니다.
말이 어렵게 되어버렸는데, 예제로 설명하겠습니다.
scanf("%d %d", &a, &b);
숫자값, 1자 이상의 공백문자, 숫자값이 입력버퍼에 있기를 기대한다.
숫자값, 1자 이상의 공백문자, 숫자값까지 읽어들인다. 그 나머지는 입력 버
퍼(stdin)에 그대로 놔둔다.
실행 결과 - 1 2를 입력했을 경우 형식(format) 문자열과 완벽히 일치한다.
그러므로 a와 b에 읽어들인 값을 저장하고 함수(scanf)를 종료한다.
scanf(%d %d\n", &a, &b);
숫자값, 1자 이상의 공백문자, 숫자값, 1자 이상의 공백문자, 공백문자가 아
닌 문자가 입력버퍼에 있기를 기대한다.
숫자값, 1자 이상의 공백문자, 숫자값, 1자 이상의 공백문자까지 읽어들인다.
그 나머지는 입력 버퍼(stdin)에 그대로 놔둔다.
실행 결과 - 1 2를 입력했을 경우 "%d %d"까지 일치가 되지만 \n 문자 때문에
1자 이상의 공백문자와 그 뒤에 공백문자가 아닌 문자를 기다리게 됩니다. 여
기에 3을 또 입력하게 되면 공백문자까지 읽어들이게 되고 나머지(3)는 그대
로 입력버퍼에 남게 됩니다. 이 남아있는 3은 다음 scanf문이 실행될 때 영향
을 주게 됩니다.
그리고 한가지 더. 다음의 예제 코드를 봐 주십시오.
#include <stdio.h>
int main(void)
{
int a, b;
printf("\n>>");
return 0;
}
이 프로그램의 실행 결과는 다음과 같습니다.
$ gcc 3.c -o 3
plsj@localhost: ~
$ ./3
>>1 2 <- 1과 2를 입력한다.
3 <- 숫자 2개가 입력되었는데도 입력을 기다린다. 3을 입력한다.
[1,2] <- 입력된 숫자 출력
>>4 5 <- 숫자 2개를 또 입력
[3,4] <- 4 5를 출력하는게 아니라 3과 4를 출력한다.
>>plsj@localhost: ~
$ ./3
>>1 2 <- 1과 2를 입력한다.
a <- 숫자 2개가 입력되었는데도 입력을 기다린다. 3을 입력한다.
[1,2] <- 입력받은 값을 출력한다.
>>[1,2] <- 여기에서 입력을 한번 받아야되는데 받지 않고 입력받은 값을
또한번 출력한다.
>>plsj@localhost: ~
$
첫번째 실행에서 1 2가 입력되면, "%d %d\n" 중에서 "%d %d"까지 일치가 됩니
다. 그러나 \n이 남아있기 때문에 1자 이상의 공백문자와 공백문자가 아닌 문
자의 입력을 기다리게 됩니다. 여기에 3을 입력하면 3 이전의 공백문자까지
읽어들이게 되어 첫번째 scanf 함수가 끝나게 되고 3은 입력버퍼에 그대로 남
습니다. 그다음의 scanf 함수가 실행되면 입력버퍼에 있는 3을 읽어들이게 되
고 " %d\n"이 남게 됩니다. 여기에 4 5를 입력하게되면 "4 "까지 읽어들이게
되고 5는 그대로 입력버퍼에 남게 됩니다. 즉 a에는 3이, b에는 4가 입력되는
것이죠.
두번째 실행에서도 마찬가지 입니다. 다만 첫번째 scanf 함수가 끝난 후에 3
대신 a가 입력버퍼에 남게 되고, 두번째 scanf 함수가 실행되면 형식(format)
문자열의 %d가 a와 일치가 안되기 때문에 두번째 scanf 함수는 하는일 없이
그대로 끝나게 됩니다. 따라서 1 2가 두번 출력되게 됩니다.
| Makefile 만들기 (0) | 2013.06.04 |
|---|---|
| TCP/IP소켓 프로그래밍 개요 및 기초소스. (0) | 2013.05.22 |
| Stack 과 heap (메모리구조) (0) | 2013.04.19 |
| kernel 에서 쓰이는 자료구조 red black tree (3) | 2013.04.19 |
| Visual studio가 잊어버리게 하는 개념(compile with gcc) (0) | 2013.04.19 |
1. stack memory(스택메모리)
stack 이란 단어를 컴퓨터 사전에서 찾아보면 이렇게 정의되어 있습니다.
“후입선출(LIFO, Last-In, First Out)방식에 의하여 정보를 관리하는 자료구조. 스택에서는 톱(Top)이라고 불리우는 스택의 끝부분에서 자료의 삽입과 삭제가 발생한다. 즉, 스택에 자료를 삽입하게 되면 톱 위치에 삽입된 정보가 위치하게 된다. 그리고 스택에서 정보를 읽어오려 하면 스택의 톱 위치에 있는 정보가 반환된다. 따라서 스택에서는 가장 나중에 삽입된 정보가 가장 먼저 읽혀지는 특징을 가지고 있다.”
그림으로 설명하자면 밑의 그림과 같습니다. A→B→C→D 라는 순서대로 자료가 쌓이게 됩니다. 그리고 빠져 나올 때는 위에서부터 차례대로 D→C→B→A 빠져나오게 됩니다. 이러한 구조를 stack 구조라고 합니다.
| | | | | | | | | | | |
|__| |__| |__| |__| | | | |
| | | | | | |D | | | | |
|__| |__| |__| |__| |__| | |
| | | | |C | |C | |C | | |
|__| |__| |__| |__| |__| |__|
| | |B | |B | |B | |B | |B |
|__| |__| |__| |__| |__| |__|
|A | |A | |A | |A | |A | |A |
|__| |__| |__| |__| |__| |__|
이러한 스택구조가 실생활에서 쓰이는 예로는 택시에서 볼 수 있는 동전을 넣는 원형통입니다. 동전은 원통형의 공간에 들어가고, 원통 아래쪽엔 스프링이 달려서 동전을 밀어 내줍니다. 손님에게 동전을 거슬러 줄 때 위에서부터 동전이 하나씩 나오게 되죠. 그럼 버스에서 보게 되는 동전교환기도 스택일까요? 이것은 스택이 아니라 큐라는 구조 입니다. 원통에 동전이 차곡차곡 쌓여있고, 아래쪽 동전부터 빠져나오게 됩니다.
즉 여기서 동전을 처음에 넣는 것을 push 라는 단어를 사용하게 됩니다.
push : 하나의 데이터를 스택에 추가한다.
그리고 동전을 꺼내는 것을 pop 이라고 합니다
pop : 하나의 데이터를 스택에서 꺼낸다.
보통 스택구조를 LIFO 라고 합니다. 즉 Last In First Out 입니다. 말 그대로 마지막에 저장한 데이터는 처음 얻어진다는 뜻입니다. 처음 집어넣은 데이터는 제일 마지막에 얻어지게 되겠지요. 이러한 방식이 컴퓨터에서는 메모리 영역 한 부분이 이런 식으로 동작하고 그 메모리 영역을 스택이라고 부르는 것입니다. 스택을 생각해 내지 못했다면 많은 변수의 사용이나, 함수 호출은 할 수가 없었을 것입니다. 그리고 스택은 프로세스가 생성될 때 필요한 만큼이 할당되어 집니다. 즉 고정사이즈 입니다. 스택 오버플로우라던가, 스택 언더플로우는 스택이 고정사이즈이기 때문에 발생하는 에러입니다.
위에서 프로세스 생성시에 스택은 정적으로 프로세스 공간에 할당 된다고 하였습니다. 그리고 스택은 내부에서도 할당과 반환이 이루어 집니다. 예를들어 스택공간이 1000byte라고 한다면 이 스택의 상대적인 주소값은 0~999까지 갖을 수 있습니다. 이 비어있는 스택에 1바이트 값을 하나 넣어주면 1바이트가 할당되는 것이라고 할 수 있습니다. 1바이트 값을 하나 스택에서 빼오는 것은 스택에서 1바이트를 반환하는 것으로 생각 할 수 있습니다. 이런 스택의 할당과 반환을 처리하기 위해서 CPU에서는 “스택 포인터”라는 레지스터가 있습니다. 이 스택포인터란 것으로 스택이 작동하며 위에서는 1byte 넣고 빼고 하는 예를 들었는데 스택 포인터를 조작하여 스택 내부에 가변적인 크기를 할당해 놓을 수도 있습니다.
그럼 일반적으로 스택이 사용되는 예를 알아보도록 하겠습니다.
스택이라는 메모리 공간에는 우리가 변수로 잡아준 것들이 위에서 설명한 방식으로 할당되고 반환됩니다. 외부 정적 변수를 제외하고 보통 자동변수라고 함수 내에서 선언하는 변수들은 스택 내부에 확보됩니다. 그리고 고정되게 위치하는 것이 아니고 동적으로 스택에 확보가 됩니다.
int ABC;
위의 ABC 변수는 4바이트가 스택에 확보되고 그 스택메모리가 변수로 사용됩니다. 블록이 닫히는 지점에서 스택 포인터 값이 변경되며 확보되어있던 부분이 소멸되지요.
배열변수도 마찬가지 입니다.
void func(void)
{
char DEF[10];
}
프로그램이 func() 로 실행될때 스택에 10바이트를 할당하고 그 할당된 스택 메모리가 변수를 담는 공간으로 이용됩니다. 물론 10바이트만 할당 되는 것은 아닙니다. 함수호출 자체가 스택을 사용하기 때문에 기본적으로 확보되어야 할 스택에다가 덤으로 10바이트를 할당합니다.
변수가 항상 스택에 할당 되는 것은 아닙니다. 하지만 대체로 스택에 할당 됩니다.
또한 포인터 변수에서도 사용이 됩니다. 포인터 변수라고 특별난 것은 없고 그냥 일반 변수처럼 포인터 변수 또한 스택이라는 공간에 잡힙니다. 단지 포인터 변수는 그 변수에 담겨있는 값이 메모리 주소값 이라는 것뿐입니다. 포인터 변수는 그냥 일반 변수와 똑같고, 사이즈는 언제나 32비트입니다. 안에 담겨있는 값이 단지 주소라는 것 뿐입니다. 변수 자체는 일반변수처럼 스택에 할당됩니다. 단지 C 라는 컴파일러에서 포인터 변수라는 의미를 부여하는 것입니다.
또한 함수 호출 후 복귀 할 때도 사용이 됩니다. 함수를 호출하기 직전에 프로그램 카운터 값을 스택에 한번 넣어주고 호출하게 됩니다. 그 호출된 함수고 종료되어 리턴되면 CPU는 스택에서 최근 넣어진 프로그램 카운터 값을 빼오고 현재의 프로그램 카운터를 빼온 값으로 변경하여 실행하게 됩니다. 그럼 프로그램은 함수 호출 후에 다시 원래대로 카운트 증가해 나가면서 실행되는 것입니다. 이것이 함수 호출의 원리이고, 스택메모리가 사용되는 예입니다.
여기서 주의할 점은 스택에 생성된 메모리는 선언된 함수나 블록문이 끝나면 자동해제됩니다.
2. heap memory(힙메모리)
heap memory 는 컴퓨터 사전을 찾아보면 이렇게 정의되어 있습니다.
“ 프로그램의 실행 도중에 요구되는 기억 장소를 할당하기 위하여 운영 체제에 예약되어 있는 기억 장소 영역. 프로그램에서 실행 도중에 자료를 저장하기 위하여 기억 장소를 요청하게 되면 운영 체제에서는 힙에 존재하는 기억 장소를 프로그램에 할당한다. 그리고 프로그램에서 기억 장치를 더 이상 필요로 하지 않는 경우에는 앞에서 할당 받았던 기억 장소를 운영체제에 반납하게 되는데, 이때 운영체제에서는 반납된 기억 장소를 다시 힙에 연결하게 된다. 힙에 대한 기억 장소는 포인터를 통해 동적으로 할당되거나 반환이 되는데 연결 리스트, 트리, 그래프 등과 같이 동적인 특성을 가지고 있는 자료구조에서 널리 사용된다.”
힙은 프로그램이 실행될 때까지 알 수 없는 가변적인 양만큼의 데이터를 저장하기 위해 프로그램의 프로세스가 사용할 수 있도록 미리 예약되어 있는 메인 메모리의 영역입니다. 예를들면 하나의 프로그램은 처리를 위해 한명 이상의 사용자로부터 서로 다른 양의 입력을 받을 수 있으며 즉시 모든 입력데이터에 대해 처리를 시작합니다. 운영체계로부터 이미 확보된 일정량의 힙 저장공간을 가지고 있으면 저장과 관련된 처리를 좀 더 쉽게 할 수 있으며 일반적으로 필요할 때마다 운영체계의 운영체계에게 매번 저장공간을 요청하는 것보다 빠르게 됩니다. 프로세스는 필요할 때 heap 블록을 요구하고 더 이상 필요 없을 때 반환하며 이따금씩 자투리 모으기를 수행함으로써 자신에게 할당된 heap을 관리하기도 합니다. 여기서 자투리 모으기란 더 이상 사용되지 않는 블록들을 사용 가능한 상태로 만들고 또한 heap 내의 사용 가능한 공간을 인지함으로써 사용되지 않은 작은 조각들이 낭비되지 않도록 하는 것을 말합니다.
힙이란 컴퓨터의 기억 장소에서 그 일부분이 프로그램들에 할당되었다가 회수되는 작용이 되풀이 되는 영역입니다. 스택영역은 엄격하게 후입선출(LIFO)방식으로 운영되는데 비해 힙은 프로그램들이 요구하는 블록의 크기나 요구/횟수 순서가 일정한 규칙이 없다는 점이 다릅니다. 대개 힙의 기억장소는 포인터변수를 통해 동적으로 할당받고 돌려줍니다. 이는 연결 목록이나 나무, 그래프 등의 동적인 자료 구조를 만드는데 꼭 필요한 것입니다.
그럼 힙 메모리를 프로그램을 사용할 수 있는 자유메모리라고 할 수 있습니다. 프로그램 실행 시에 함수로 내는 데이터 등을 일시적으로 보관해 두는 소량의 메모리와 필요시 언제나 사용할 수 있는 대량의 메모리가 있습니다. 이때, 소량의 메모리를 ‘스택’이라 하고 대량의 메모리를 ‘힙’ 이라고 합니다. 이 ‘힙’이 없어지면 메모리 부족으로 ‘이상종료’를 하게 됩니다.
프로세스에 exe 이미지가 로드되고, 할당되고, 이것저것 필요한 동적 라이브러리가 로드되고 사용되지 않는 미사용 구간이 있는 것은 분명한데 그 미사용 영역이 ‘힙’이라고 합니다. 프로그램을 짤 때 new나 malloc()함수를 이용한 동적 할당을 하게 되면 힙 영역이 사용 가능하도록 되는 것입니다. 님께서 물어보신 생성자, 소멸자 역시 힙 영역에 메모리를 할당하고 해제하는것입니다. 필요한 메모리 사이즈만큼 OS에게 할당해 달라고 부탁할 수도 있으며, 사용을 다 했으면 다시 OS에게 넘겨줘야 합니다.
예를들어
char *p = new char[1000];
위와 같은 코드가 런타임시 힙영역에 메모리를 1000바이트 할당하는 동작을 합니다. 물론 할당을 하였으면 반환도 해주어야 겠지요. 참고로 힙을 마구 할당하고 반환시키다가 보면 선형 메모리의 중간중간이 끊어지게 됩니다. 즉 다른말로 표현하자면 메모리 블록이 여러조각으로 나뉘게 되어 비효율적으로 되어버리기도 합니다.
힙 메모리는 프로그램이 종료 될 때까지 관리하고 유지 되는 메모리 영역이기 때문에 전역함수를 쓰지 않고 프로그램 내에서 지속적으로 메모리를 참조해야 할 경우 힙 영역에 메모리를 할당 받으면 됩니다.
| TCP/IP소켓 프로그래밍 개요 및 기초소스. (0) | 2013.05.22 |
|---|---|
| scanf 의 입력개념 (0) | 2013.04.20 |
| kernel 에서 쓰이는 자료구조 red black tree (3) | 2013.04.19 |
| Visual studio가 잊어버리게 하는 개념(compile with gcc) (0) | 2013.04.19 |
| Vi 편집기 setting (0) | 2013.04.19 |
 |
|
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
